



前言:
用8核32G的服务器(无独显)部署的deepseek-R1-32b的模型,体验上真的是一言难尽。先不管回答的怎么样,而是输出的速度真的很慢,所以如果没有性能强劲的独立显卡和机器还是不要自己本地部署,这里只是提供ubuntux系统的部署流程,在实际使用过程中并没有太大的意义。
一、部署Ollama(多平台选择安装)
Ollama 支持 Linux/macOS/Windows,需根据系统选择安装方式。
.1. Linux 系统部署
适用系统:Ubuntu/Debian/CentOS 等
步骤:
1-1.一键安装:
curl -fsSL https://ollama.com/install.sh | sh
1-2.权限配置(避免 sudo 运行):
sudo usermod -aG ollama $USER # 将当前用户加入ollama组newgrp ollama # 刷新用户组
1-3.启动服务:
systemctl start ollama # 启动服务systemctl enable ollama # 开机自启
1-4.验证安装:
ollama --version # 输出版本号即成功
二.配置远程Ollama服务
默认情况下,Ollama 服务仅在本地运行,不对外提供服务。要使 Ollama 服务能够对外提供服务,需要设置以下两个环境变量:
2-1.如果 Ollama 作为 systemd 服务运行,应使用 systemctl 设置环境变量:(路径:/etc/systemd/system/ollama.service)
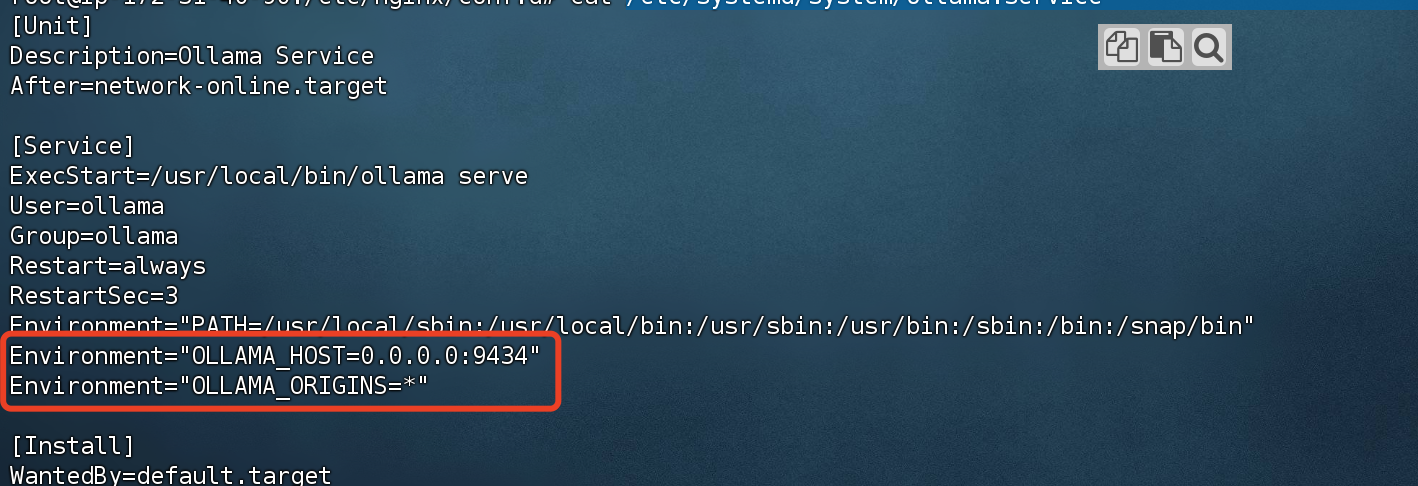
Environment=“OLLAMA_HOST=0.0.0.0:9434”
Environment=“OLLAMA_ORIGINS=*”
端口号可以自定义,防止使用默认端口出现安全风险。
2-2.修改配置环境
vim /etc/profile
image-1740395768002
在最后两行加上
export OLLAMA_HOST=0.0.0.0:9434
ulimit -SHn 65535
保存退出 重启配置
source /etc/profile
重新加载 systemd 并重启 Ollama:
systemctl daemon-reload
systemctl restart ollama
输入ollama list就可以看到模型数据了。

三.拉取并运行DeepSeek模型
3-1.拉取模型
ollama pull deepseek-r1-32b

3-2.运行模型
ollama run deepseek-r1-32b
验证交互:

四、不同硬件场景配置说明
根据硬件资源选择运行模式:
场景1:纯CPU运行
适用情况:无独立显卡或显存不足
配置优化:
1.限制线程数(避免资源耗尽):
OLLAMA_NUM_THREADS=4 ollama run deepseek-r1 # 限制4线程
2.使用量化模型(减少内存占用):
ollama pull deepseek-r1:7b-q4_0 # 4-bit量化版
内存要求:
- 7B模型:至少8GB空闲内存
- 33B模型:至少32GB空闲内存
场景2:CPU+GPU混合运行
适用情况:有NVIDIA显卡(需CUDA支持)
配置步骤:
1.安装驱动:
2.安装 NVIDIA驱动 和 CUDA Toolkit 12.x
3.启用GPU加速:
ollama run deepseek-r1 --gpu # 强制使用GPU
4.显存要求:
- 7B模型:至少6GB显存
- 33B模型:至少20GB显存
5.性能监控:
nvidia-smi # 查看GPU利用率
评论区